Nel panorama sempre più competitivo dell'intelligenza artificiale, un nuovo protagonista si fa strada: Yuan 3.0 Flash. Sviluppato dal team YuanLab.ai, questo modello multimodale rappresenta una svolta per le aziende che cercano prestazioni di livello enterprise a costi contenuti.
Ma cosa rende Yuan 3.0 Flash così interessante per il mondo business? La risposta sta nella sua architettura innovativa e nei risultati sorprendenti ottenuti nei benchmark aziendali, dove supera perfino GPT-5.1 in diversi task critici.
In questa guida completa scopriamo cos'è Yuan 3.0 Flash, come funziona, quali vantaggi offre alle aziende e come integrarlo nei processi di lavoro quotidiani.
Cos'è Yuan 3.0 Flash e Perché è Rivoluzionario
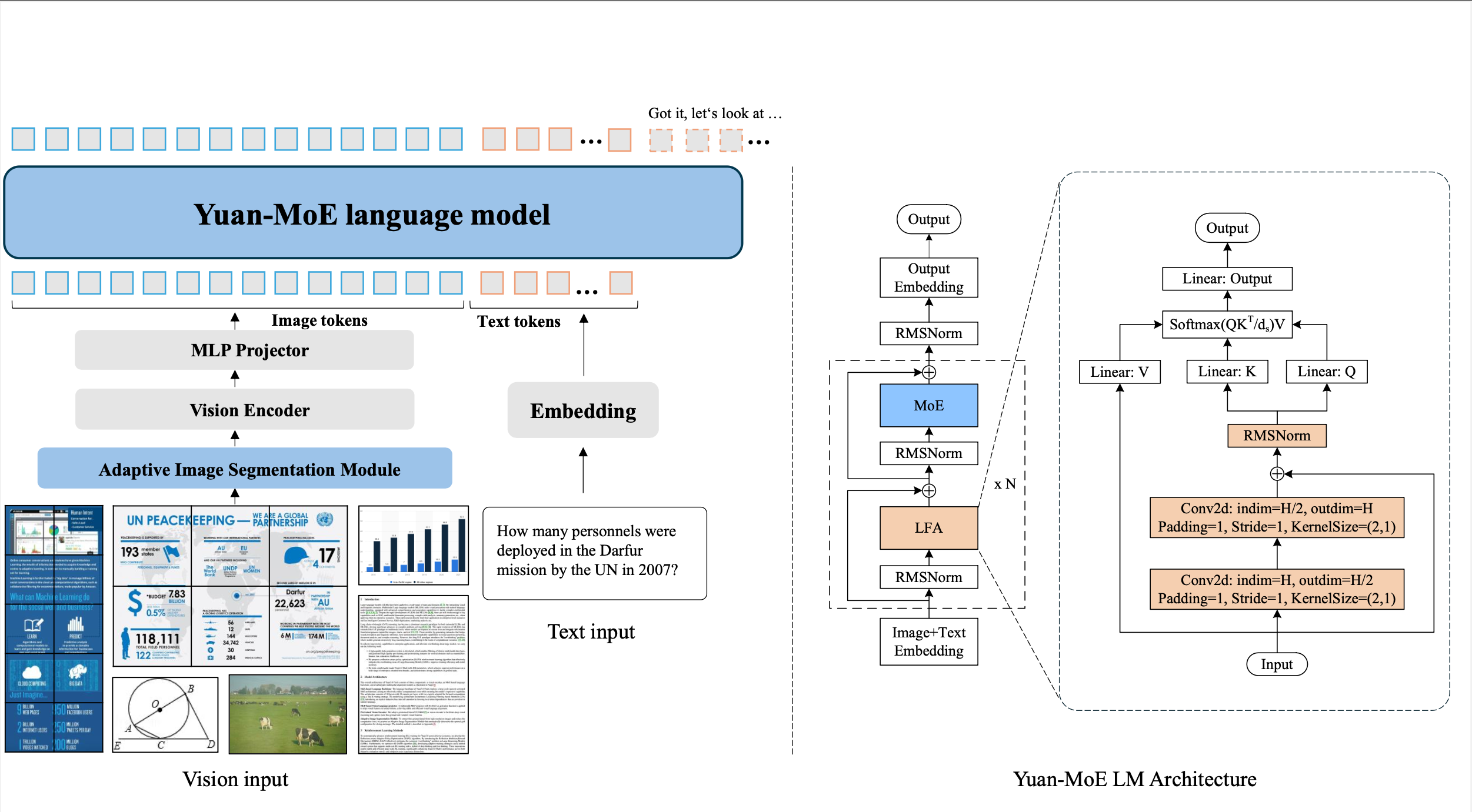
Yuan 3.0 Flash è un modello di linguaggio (LLM) con 40 miliardi di parametri totali, rilasciato il 30 dicembre 2025. La sua particolarità principale risiede nell'architettura Mixture of Experts (MoE), una tecnologia che attiva solo circa 3,7 miliardi di parametri per ogni inferenza.
Questo significa che, pur avendo la potenza di un modello da 40B, il consumo computazionale effettivo è paragonabile a quello di modelli molto più piccoli. Il risultato? Prestazioni di alto livello con costi energetici e computazionali drasticamente ridotti.
L'Algoritmo RAPO: Meno Token, Più Precisione
Una delle innovazioni più significative di Yuan 3.0 Flash è l'algoritmo RAPO (Reflection-aware Adaptive Policy Optimization). Questo sistema di apprendimento per rinforzo risolve un problema comune nei modelli di ragionamento: l'overthinking, ovvero la tendenza a continuare a elaborare anche dopo aver trovato la risposta corretta.
Attraverso il meccanismo RIRM (Reflection Inhibition Reward Mechanism), l'algoritmo identifica il momento esatto in cui viene ottenuta la risposta corretta e sopprime i ragionamenti ridondanti successivi. I risultati sono impressionanti: una riduzione del consumo di token fino al 75% mantenendo o addirittura migliorando l'accuratezza.
Prestazioni e Benchmark: I Numeri Parlano Chiaro
Yuan 3.0 Flash non è solo promesse teoriche. I test indipendenti dimostrano performance superiori ai concorrenti più blasonati in diversi scenari enterprise.
RAG Testuale: Benchmark ChatRAG
Nel benchmark ChatRAG, lo standard di riferimento per applicazioni RAG (Retrieval-Augmented Generation), Yuan 3.0 Flash raggiunge una precisione media del 64,47% su 10 task di valutazione. Per confronto, DeepSeek-V3 si ferma al 50,47% e GPT-4o al 50,54%.
RAG Multimodale: Benchmark Docmatix
Nel benchmark Docmatix, che valuta la capacità di recuperare informazioni da documenti complessi multi-pagina con testo, tabelle e immagini, Yuan 3.0 Flash ottiene il 65,07%, superando GPT-4o (56,79%) e Qwen2.5-VL-72B (59,75%).
Comprensione Tabelle: Benchmark MMTab
Per l'analisi di tabelle complesse, scenario critico nell'automazione degli uffici, Yuan 3.0 Flash raggiunge il 58,29% su 15 task, battendo GPT-5.1 (55,15%) e posizionandosi primo in oltre metà dei test.
Generazione Riassunti: Benchmark SummEval
Nella generazione automatica di riassunti, competenza fondamentale per agenti AI e chatbot aziendali, Yuan 3.0 Flash ottiene un punteggio medio del 59,31%, superando DeepSeek-V3 (59,28%) e GPT-5.1 (49,44%).
Caratteristiche Tecniche Principali
Ecco le specifiche che rendono Yuan 3.0 Flash adatto all'utilizzo enterprise:
- Parametri totali: 40 miliardi con architettura MoE
- Parametri attivi per inferenza: circa 3,7 miliardi (9,25% di sparsità)
- Contesto supportato: fino a 128.000 token con 100% di accuratezza nei test "Needle in a Haystack"
- Input supportati: testo, immagini, tabelle, documenti PDF
- Licenza: open source con uso commerciale consentito senza autorizzazione
- Formati disponibili: HuggingFace 16bit e versione quantizzata 4bit
Come Usare Yuan 3.0 Flash: Guida Pratica
L'integrazione di Yuan 3.0 Flash nei flussi aziendali è relativamente semplice grazie alla disponibilità di diversi formati e alla compatibilità con framework popolari.
Download e Installazione
Il modello è disponibile gratuitamente su tre piattaforme principali: HuggingFace (YuanLabAI/Yuan3.0-Flash), ModelScope (Yuanlab/Yuan3.0-Flash) e WiseModel. Per chi ha risorse hardware limitate, è disponibile anche la versione quantizzata a 4bit.
Requisiti Hardware
Per eseguire Yuan 3.0 Flash in modo efficiente servono GPU con supporto MoE. I framework consigliati includono DeepSpeed MoE e Megatron-LM. La versione completa a 16bit richiede hardware significativo, mentre la versione 4bit può girare su configurazioni più accessibili.
Inferenza con vLLM
Il repository ufficiale fornisce script pronti all'uso per l'inferenza tramite vLLM. È possibile scegliere tra modalità "thinking" (con ragionamento esplicito) e "non-thinking" (risposta diretta) in base alle esigenze dell'applicazione.
Fine-Tuning Personalizzato
Per adattare il modello a specifici domini aziendali, Yuan 3.0 Flash supporta il fine-tuning supervisionato (SFT) e l'apprendimento per rinforzo. La documentazione include script e workflow completi per il training personalizzato.
Casi d'Uso Aziendali
Yuan 3.0 Flash eccelle in diversi scenari enterprise. Vediamo i principali:
Assistenza Clienti Intelligente
Grazie alle eccellenti prestazioni RAG, il modello può alimentare chatbot capaci di recuperare informazioni da knowledge base aziendali con alta precisione, rispondendo a domande complesse su prodotti, procedure e politiche.
Analisi Documentale
La capacità multimodale permette di processare documenti PDF, contratti, report finanziari ed estrarre informazioni chiave. Particolarmente utile per studi legali, commercialisti e uffici amministrativi che gestiscono grandi volumi di documentazione.
Elaborazione Tabelle e Dati
I risultati eccezionali nel benchmark MMTab lo rendono ideale per l'analisi di spreadsheet, report finanziari, tabelle di dati. Può estrarre insight, rispondere a domande specifiche e generare riassunti dai dati tabulari.
Generazione Report e Sintesi
Per chi deve produrre report periodici, riassunti di riunioni o sintesi di documenti lunghi, Yuan 3.0 Flash offre capacità di summarization superiori ai competitor, mantenendo coerenza semantica e accuratezza fattuale.
Automazione Workflow
Integrato in piattaforme di automazione come n8n, può diventare il motore intelligente di flussi automatizzati per la gestione email, categorizzazione ticket, estrazione dati e molto altro.
Confronto con Altri Modelli: Quando Scegliere Yuan 3.0 Flash
Come si posiziona Yuan 3.0 Flash rispetto alla concorrenza? Ecco un'analisi comparativa:
Vs GPT-4o e GPT-5.1
Yuan 3.0 Flash supera entrambi nei task RAG e comprensione tabelle, pur essendo open source e gratuito. I modelli OpenAI restano preferibili per task generali e creativi, ma per applicazioni enterprise specifiche Yuan offre il miglior rapporto qualità-prezzo.
Vs DeepSeek-V3 e DeepSeek-R1
Nei benchmark testati, Yuan 3.0 Flash surclassa DeepSeek in RAG e summarization. DeepSeek mantiene vantaggi in altri ambiti come coding e ragionamento matematico. Per applicazioni documentali e aziendali, Yuan è la scelta migliore.
Vs Claude 3.5 Sonnet
Nel benchmark Docmatix per RAG multimodale, Yuan 3.0 Flash (65,07%) supera nettamente Claude 3.5 Sonnet (42,55%). Per elaborazione documentale enterprise, Yuan rappresenta un'alternativa più performante e gratuita.
Vantaggi per le PMI Italiane
Per le piccole e medie imprese italiane, Yuan 3.0 Flash rappresenta un'opportunità unica:
- Costo zero per la licenza: a differenza dei servizi API a pagamento, il modello è completamente gratuito
- Privacy dei dati: eseguibile on-premise, i dati aziendali non escono mai dall'infrastruttura
- Efficienza energetica: il 75% in meno di token significa bollette cloud ridotte
- Personalizzazione: possibilità di fine-tuning per adattarlo al proprio settore e terminologia
- Contesto lungo: 128K token permettono di elaborare documenti lunghi senza frammentarli
Limitazioni e Considerazioni
Prima di adottare Yuan 3.0 Flash è importante considerare alcune limitazioni:
- Hardware specializzato: per prestazioni ottimali servono GPU con supporto MoE e kernel ottimizzati
- Task generali: in alcuni benchmark zero-shot generici, i modelli proprietari mantengono un vantaggio
- Supporto: essendo open source, il supporto dipende dalla community e dalla documentazione
- Lingua: sviluppato primariamente per cinese e inglese, le performance in italiano potrebbero variare
Come Iniziare: Primi Passi
Ecco un percorso consigliato per iniziare a sperimentare con Yuan 3.0 Flash:
- Fase 1: Scarica la versione 4bit da HuggingFace per test iniziali con requisiti hardware ridotti
- Fase 2: Sperimenta con gli script di inferenza del repository GitHub ufficiale
- Fase 3: Identifica un caso d'uso specifico (es. chatbot su documentazione interna)
- Fase 4: Valuta il fine-tuning con dati aziendali per migliorare le performance nel tuo dominio
- Fase 5: Integra in produzione con monitoraggio delle metriche di qualità e costi
Leggi anche
- Prompt Repetition: La Tecnica Semplice che Migliora gli LLM
- Microsoft Copilot Studio per VS Code: Agenti AI Come Codice
- Claude Cowork Disponibile per Abbonati Pro da 20$/Mese
- TranslateGemma: Google Lancia l'AI Open Source per Traduzioni
Conclusioni
Yuan 3.0 Flash rappresenta un passo avanti significativo nel rendere l'intelligenza artificiale enterprise accessibile. Con prestazioni che superano GPT-5.1 in task aziendali chiave, costi ridotti del 75% e licenza open source, offre alle aziende italiane un'alternativa concreta ai servizi a pagamento.
Se stai valutando l'integrazione di AI nei processi aziendali e vuoi capire come implementare soluzioni su misura per la tua attività, contattami per una consulenza. Insieme possiamo identificare i casi d'uso più adatti e costruire una strategia di adozione graduale e sostenibile.


