Chiunque abbia utilizzato ChatGPT, Claude o Gemini conosce il problema: più lunga è la conversazione, più il modello sembra "dimenticare" le informazioni iniziali. Questo fenomeno, noto come context rot, rappresenta una delle sfide più importanti nel campo dell'intelligenza artificiale. Ma i ricercatori del MIT potrebbero aver trovato una soluzione rivoluzionaria.
Nel paper "Recursive Language Models" (arXiv:2512.24601), Alex Zhang, Tim Kraska e Omar Khattab del MIT presentano una tecnica innovativa che permette ai Large Language Model di elaborare input potenzialmente infiniti, superando i limiti fisici della context window.
Il Problema della Context Window: Perché gli LLM "Dimenticano"
Ogni modello linguistico ha un limite massimo di token che può elaborare in una singola richiesta. Claude Opus può gestire fino a 200.000 token, mentre Gemini arriva oltre il milione. Tuttavia, c'è un problema fondamentale: all'aumentare della lunghezza del contesto, le performance degradano significativamente.
Questo fenomeno viene chiamato "Lost in the Middle" o context rot. In pratica, quando un LLM deve elaborare enormi quantità di testo, perde progressivamente il "focus" sulle informazioni rilevanti. È come cercare di leggere un'intera enciclopedia memorizzandola parola per parola: a un certo punto, le prime pagine diventano un ricordo sfumato.
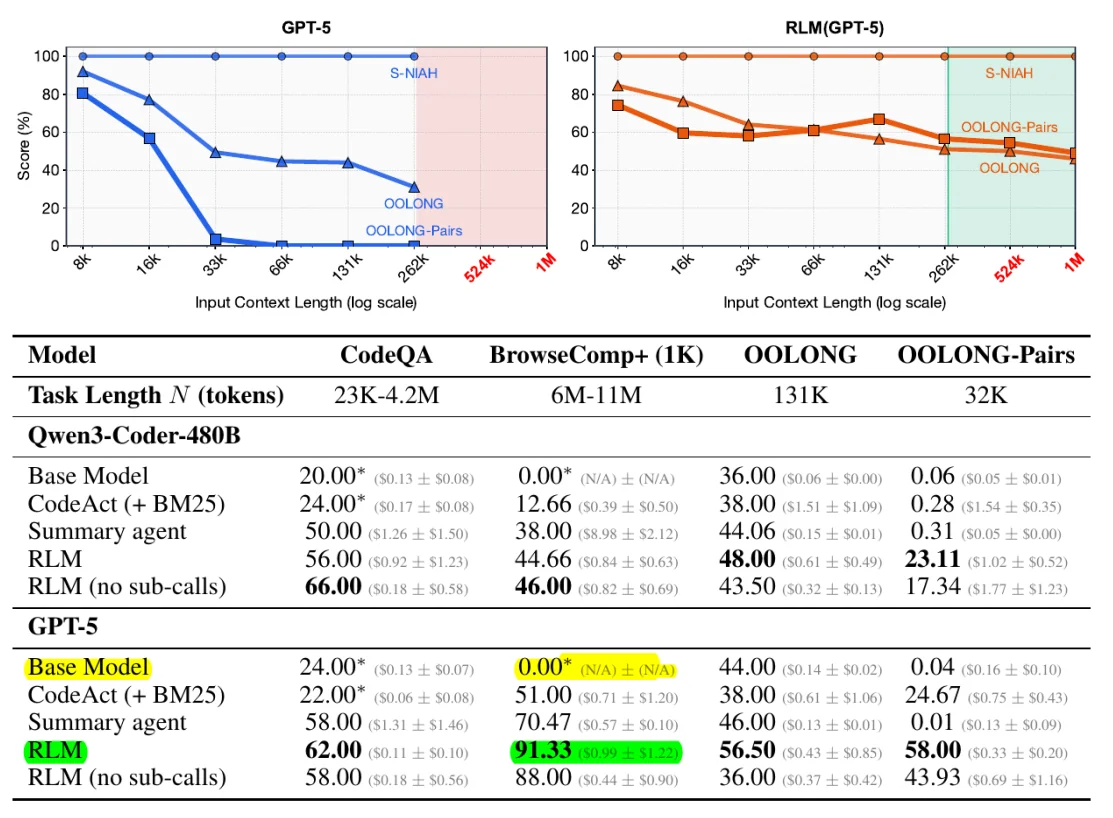
I test dimostrano che anche i modelli più avanzati vedono la loro accuratezza crollare quando il contesto supera determinate soglie. Su benchmark come OOLONG, modelli come GPT-5 mostrano un F1 score che precipita dallo 0.04 quando elaborano contesti molto lunghi in modo tradizionale.
La Soluzione Rivoluzionaria del MIT: i Recursive Language Model
L'intuizione geniale dei ricercatori del MIT è semplice ma potente: invece di caricare tutto il testo direttamente nella context window, il contenuto viene trattato come una variabile esterna all'interno di un ambiente Python REPL (Read-Eval-Print Loop).
In altre parole, il modello non "ingurgita" l'intero documento in un colpo solo. Al contrario, scrive snippet di codice Python per esplorare, sezionare e analizzare il testo in modo programmatico. Pensalo come la differenza tra memorizzare un libro e consultarlo con un indice intelligente.
Come Funziona Tecnicamente un RLM
Il funzionamento dei Recursive Language Model si basa su alcuni principi chiave:
- Il prompt come variabile: L'intero input viene memorizzato come stringa in una variabile Python, non nel contesto del modello
- Esplorazione programmatica: L'LLM scrive codice per ispezionare porzioni specifiche del testo usando cicli for, regex o ricerche per keyword
- Chiamate ricorsive: Il modello può invocare se stesso (o versioni più piccole) su sottosezioni del documento
- Aggregazione dei risultati: Le informazioni estratte vengono combinate per formulare la risposta finale
Per esempio, se deve analizzare un documento di 10 milioni di token, l'RLM potrebbe prima suddividerlo in capitoli, poi esplorare i capitoli rilevanti, infine approfondire i paragrafi specifici. È come un ricercatore che usa l'indice di una biblioteca per trovare esattamente ciò che cerca, invece di leggere ogni singolo libro.
Non è RAG: Ecco la Differenza Sostanziale
Molti potrebbero confondere i Recursive Language Model con il RAG (Retrieval-Augmented Generation), ma sono approcci fondamentalmente diversi. Il RAG si basa su un sistema di indicizzazione e retrieval esterno che seleziona i chunk più rilevanti prima di passarli al modello.
I RLM, invece, permettono al modello stesso di decidere dinamicamente cosa esaminare, come farlo e in quale ordine. L'LLM mantiene il controllo completo del processo di analisi, adattandosi in tempo reale alla complessità del task. Non c'è pre-processing fisso: ogni query può generare un pattern di esplorazione diverso.
Inoltre, mentre il RAG soffre quando le informazioni rilevanti sono sparse o richiedono ragionamenti su più parti del documento, gli RLM eccellono proprio in questi scenari grazie alla loro capacità di aggregazione programmatica.
Risultati Sorprendenti: Performance Stabili a Ogni Scala
I test condotti dai ricercatori del MIT hanno prodotto risultati impressionanti. Su benchmark come OOLONG e BrowseComp-Plus, gli RLM hanno dimostrato:
- GPT-5-mini con RLM supera GPT-5 standard del 110% su sequenze da 132.000 token
- Performance stabili fino a 10+ milioni di token, dove i modelli tradizionali falliscono completamente
- Costi comparabili o inferiori rispetto alle chiamate dirette al modello
- F1 score di 58.00 con RLM contro 0.04 del modello base su task complessi (OOLONG Pairs)
Il dato più significativo è che la complessità computazionale passa da lineare O(N) a potenzialmente logaritmica O(log N) per task di retrieval, perché l'RLM può applicare strategie di ricerca binaria sul contenuto.
L'Analogia della Biblioteca: Capire gli RLM in Modo Intuitivo
Per comprendere meglio il concetto, immagina di dover trovare un'informazione specifica all'interno di un'intera biblioteca. L'approccio tradizionale degli LLM sarebbe come cercare di memorizzare ogni singola parola di ogni libro contemporaneamente: inevitabilmente faresti confusione.
Con i Recursive Language Model, invece, ti viene fornito un assistente robotico a cui puoi dare istruzioni scritte. Questo assistente può consultare cataloghi, prendere appunti, saltare da un libro all'altro e leggerti solo i paragrafi pertinenti. Non importa quanti libri ci siano nella biblioteca: la tua capacità di analisi resterà sempre lucida e precisa.
Implicazioni per il Futuro dell'AI
I Recursive Language Model rappresentano un cambio di paradigma nel modo in cui concepiamo l'interazione tra LLM e grandi quantità di dati. Le implicazioni pratiche sono enormi:
- Analisi di codebase complesse: Repository con milioni di righe di codice possono essere analizzati senza perdita di contesto
- Ricerca scientifica: Interi archivi di paper possono essere esplorati per trovare connessioni tra studi
- Elaborazione documentale: Contratti, report finanziari e documentazione legale di qualsiasi dimensione
- Long-horizon agents: Agenti AI che possono mantenere contesto su settimane o mesi di lavoro
Prime Intellect ha già implementato una variante degli RLM nel loro framework RLMEnv, mentre il codice ufficiale è disponibile su GitHub. I ricercatori suggeriscono che combinando gli RLM con il reinforcement learning si potrebbero ottenere risultati ancora più impressionanti.
Context Folding: Il Nuovo Paradigma del 2026
Gli esperti del settore stanno già definendo il context folding come il paradigma dominante del 2026. A differenza della semplice compressione o summarization del contesto (che comporta inevitabilmente perdita di informazioni), il context folding permette al modello di gestire attivamente la propria memoria di lavoro.
Strumenti come Claude e altri assistenti AI potranno beneficiare enormemente di questa tecnologia, specialmente in ambiti dove la precisione è fondamentale come la sanità o la finanza.
Leggi anche
- Anthropic vs OpenAI: La Guerra dell'AI nella Sanità
- Perché l'IA Non Riesce a Disegnare Orologi: Il Mistero del 10:10
- Gemini Supera ChatGPT: Google Domina l'IA nel 2026
- Grok Limita le Immagini AI Gratis: La Crisi Deepfake Colpisce X
Conclusioni: Una Svolta Epocale per gli LLM
I Recursive Language Model rappresentano una delle innovazioni più significative nel campo dell'intelligenza artificiale degli ultimi anni. Non si tratta semplicemente di aumentare la dimensione della context window, ma di ripensare completamente il modo in cui i modelli linguistici interagiscono con i dati.
La capacità di elaborare 10 milioni di token o più senza degradazione delle performance apre scenari applicativi finora impensabili. Per le aziende che lavorano con grandi quantità di dati, questa tecnologia potrebbe essere trasformativa.
Stai sviluppando un progetto che richiede l'elaborazione di grandi volumi di testo o dati? Contattami per una consulenza personalizzata su come integrare le più recenti tecnologie AI nel tuo business.


